
|
April 8, 2024 We have a new paper at EURALEX 2024!
Próximo 3 de abril de 2024 Conferencia de Carles Tebé en la inauguración del Doctorado en Lingüística PUCV
20 de marzo de 2024 Jornada de Investigación sobre Análisis de Metáforas en Corpus
29 de enero de 2024 Seminario en Santiago de Compostela
December 31, 2023 And we say good by to 2023 with yet another paperDecember 28, 2023 We have new paper about Termout.org
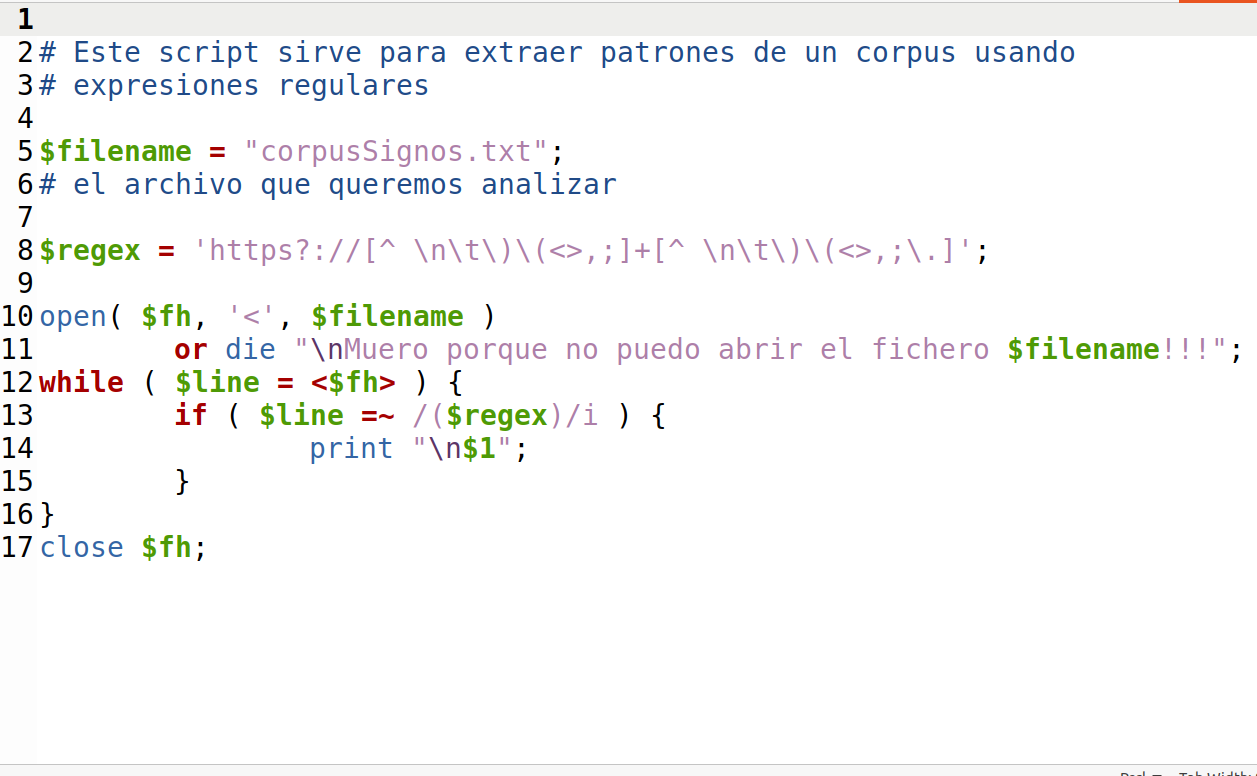
December 4, 2023 We released the regex Perl script
November 28, 2023 We just finished the very first corpus linguistics course at PUCV.cl
November 22, 2023 WOPATEC is happening right now!
10 de noviembre, 2023 Javier Obreque e Ignacio Lobos presentan su investigación sobre herramientas de retroalimentación automática de la escritura
3 de noviembre, 2023 Se publica el manual de Lexicografía hispánica de Routledge
27 de octubre, 2023 Tesis de Javier Obreque gana concurso internacional ALED
20 October, 2023 New web-interface for Poppins, our text classifier
|
Tools & demosWe have implemented different types of applications and most of them can be tested online. Take a look. + Compare: a simple script to compare two lists of words + Cryptoman: a script to generate cryptograms + Dismark: a multilingual taxonomy of discourse markers + Dsele: a model dictionary for ELE learners + Estilector: computer assisted writing for Spanish + GeNom: a program to detect the gender of proper nouns + HAT: a project for the treatment of polysemy in lexical taxonomies + Jaguar: a tool for statistic corpus analysis + Kind: a lexical taxonomy induction algorithm + Kwico: a concordancer for big corpora + Lealem: a reading pacer for parallel German-Spanish texts + Leafran: a reading pacer for parallel French-Spanish texts + Linguini: a language detector + Neven: a program to detect eventive nouns + POL: named entity recognition and classification + Poppins: a supervised text classifier (new interface!) + Porcus: an interface for various taggers and parsers for Spanish + pullPOS: a project for the detection of plurals in Spanish + Punkt: punktuation of discourse markers in Spanish + Randall: a list randomizer + Readeutsch: a reading pacer for parallel German-English texts + Regex: a Perl script for regular expressions (new!) + Sapo: a program to detect similarities between documents + Sicam: a program to analyze Spanish poetry + Termout: a terminology extraction system (new version!) + TEXT·A·GRAM: a program to analyze Spanish texts + Verbario: corpus pattern analysis in Spanish |
|||||||||||||||||||||||||












{kind=link}

This is the view from where we are located, in the Sausalito lagoon, a quiet and lovely place in Viña del Mar, Chile. Sunny days. Birds can be seen in the center of the lagoon (click to enlarge). As researchers, we are currently affiliated to:
Av. El Bosque 1290, Viña del Mar, Chile |
Upcoming Events[UPDATED: April 8, 2024]May 22-24, 2024: Irene Renau will be presenting a paper at the X Congreso Internacional de Lexicografía Hispánica, to be held at Universidad de Murcia, Spain. This time, the title of the conference is «Variación y panhispanismo en lexicografía» (Variation and pan-Hispanism in lexicography) |
Tweets by TeclingGroup | |
Latest ideas & research projects We are developing new projects in computational linguistics and natural language processing:
|
Recent publications+ Nazar, R.; Renau, I.; Robledo, H. (In press). Dismark and Text·a·Gram: Automatic identification and categorization of discourse markers in texts. In Proceedings of DISROM 2022 (Discourse Markers in Romance Languages, Craiova, 16-18 June 2022). + Obreque, J.; Nazar, R. (2023). Detección de operadores modales: una primera exploración en castellano. Linguamatica. 15(2): 37--49. PDF + Renau, Irene. (2023). A corpus-based study of semantic neology of the Covid-19 pandemic. Quaderns de Filologia: Estudis Lingüístics XXVIII: 55-76. PDF + Nazar, R. (2023). Extensión, variación y evolución del léxico español. In Battaner, P., Torner, S, Renau, I. Lexicografía hispánica / The Routledge Handbook of Spanish Lexicography. Cap. 14, pp. 204-218. + López-Hidalgo, B.; Renau, I.; Nazar, R. (2023). Correlación entre la metáfora orientacional BUENO ES ARRIBA / MALO ES ABAJO y polaridad positiva/negativa en verbos del español: un estudio con estadística de corpus. Humanidades Digitales, Corpus y Tecnología del Lenguaje. University of Groningen Press, pp. 307-323. PDF + Nazar, R. & Acosta, N. (2023). Termout: a tool for the semi-automatic creation of term databases. In Haddad, Amal; Terryn, Ayla; Mitkov, Ruslan; Rapp, Reinhard; Zweigenbaum, Pierre and Sharoff, Serge (eds.) Proceedings of the Workshop on Computational Terminology in NLP and Translation Studies (ConTeNTS) Incorporating the 16th Workshop on Building and Using Comparable Corpora (BUCC), INCOMA, Shoumen, Bulgaria, pp. 9-18. PDF + Nazar, R. & Renau, I. (2023). Estilector: un sistema de evaluación automática de la escritura académica en castellano. Revista Perspectiva Educacional, 62(2): 37-59. PDF + Robledo, H.; Nazar, R. (2023). A proposal for the inductive categorisation of parenthetical discourse markers in Spanish using parallel corpora. International Journal of Corpus Linguistics. http://doi.org/10.1075/ijcl.20017.rob + Renau, I.; Nazar, R. (2022). Towards a multilingual dictionary of discourse markers: automatic extraction of units from parallel corpus. In: Klosa-Kückelhaus, A.; Engelberg, S.; Möhrs, C.; Storjohann, P. Dictionaries and Society. Proceedings of the XX EURALEX International Congress, Mannheim: IDS-Verlag, pp. 262-272. PDF + Nazar, R; Lindemann, D. (2022). Terminology extraction using co-occurrence patterns as predictors of semantic relevance. Proceedings of the TERM21 Workshop. Language Resources and Evaluation Conference (LREC 2022), Marseille, 20-25 June 2022, pp. 26-29. PDF |
Solutions for text processingIt is critical for organizations to have the ability to process information automatically, and very often that information is contained in documents to be read by humans rather than machines. We have different methods for text processing depending on the goal. We can be helpful teaching people how to automatize their text processing routines. We can batch-process thousands of documents to extract information from them or to derive different types of statistics. We can also change these document, or generate databases or email correspondence based on information extracted from them. Anything that involves intelligent management of information can benefit from different degrees of automatization, and by doing that we can free time, effort and resources. Tell us which are your needs and we will show you what we can do about it. |
|