Dismark
Official website of Project Fondecyt 1191481
AUTOMATIC INDUCTION OF TAXONOMIES OF DISCOURSE MARKERS FROM MULTILINGUAL CORPORACurrent version: July 30, 2024
Last week we did some long awaited maintenance service of the hardware hosting this website. Everything went smoothly and we haven't encountered any bugs so far. If you detect something, please say so in an email to rogelio dot nazar at pucv dot cl.

This web site offers the following contents:
- Documentation
- A multilingual taxonomy resulting from the project
- An automatic classifier of discourse markers
AbstractProject Fondecyt Regular 1191481, with the title 'Automatic induction of taxonomies of discourse markers from multilingual corpora', was funded by Anid.cl and directed by Rogelio Nazar. It consists of a lexicographic research project aimed at cataloging discourse markers (DMs) by means of statistical analysis of large parallel corpora. It is based on a newly developed algorithm for the automatic induction of a multilingual taxonomy of DMs, which is then used to recursively identify and classify more units. The project started in April 2019 and finished in April 2022. This web site presents the results of the project, which include a multilingual taxonomy of discourse markers in English, Spanish, French, German and Catalan, as well as a computer program to detect and classify DMs.DMs have been in the spotlight of linguistic theory in recent years, with an increasing number of publications devoted on the subject (e.g. Casado Velarde, 1993; Fraser, 1999; Martín Zorraquino & Portolés, 1999; Pons Bordería, 2001; Fischer, 2006; Borreguero & López, 2010; Fedriani & Sansò, 2017; Crible & Blackwell, 2020; Furkó, 2020; Loureda et al., 2020; Haselow & Hancil, 2021). Early interest on the subject began to appear in the context of discourse analysis (Halliday & Hasan, 1976; van Dijk, 1978; Halliday, 1985), where DMs were defined as particles that facilitate the interpretation of coherence relations in texts or, in other words, instructions on how to connect propositions and organize an argumentation. They are defined, therefore, as procedural rather than conceptual or lexical units. DMs can pertain to different categories, such as conjunctions, adverbs, prepositional phrases, idioms, and so on. The way to classify DMs is according to their functions. Some of the most common are counter-argumentation, with expressions such as however or nevertheless, cause-consequence, such as consequently or therefore, and so on. In Spanish, a well-known taxonomy is the one by Martín Zorraquino & Portolés (1999), but there are others. Fewer are the attempts to compile extended lists of DMs. Some dictionaries have appeared (e.g. Santos Río, 2003; Briz, 2008; Fuentes Rodríguez, 2009; Holgado Lage, 2017). The main difference between our present research and these attempts is that ours is an empirical method, i.e., a bottom-up rather than a top-down approach. This is important for practical reasons, as the automation saves a lot of effort, buy also, and most importantly, for scientific reasons, as the quantitative method favors objectivity. The method applied in this project is purely statistical, i.e. without any type of external resource apart from a corpus, not even POS-taggers. It is a minimalistic approach based on parallel corpora, in this case Tiedemann's (2016) Opus Corpus. The method is based on co-occurrence association measures and an entropy model that quantifies the information of each DM candidate. DMs are identified according to their distribution in the corpus, and their characteristic pattern is that they are independent of the content of the text. In operational terms, this means that their occurrence cannot be used to predict the occurrence of other lexical units. They are then classified according to a novel clustering algorithm. The similarity measure used for the clustering is their shared equivalence in the parallel corpus (i.e., nevertheless and however are considered similar because they share the same equivalences in a second language). Then, the result of the clustering of the different languages is aligned to obtain a multilingual taxonomy. Once a basic taxonomy is built this way, it is then used to classify new DMs in a recursive manner. The algorithm will first classify a DM candidate by language, it will then decide if it is effectively a DM and, if this is the case, it will assign the candidate to a category. |
Research Proposal
1. Introduction
2. Related work
2.1. Research on Discourse Markers
2.3. Background of automatic categorization of DMs
2.4. Background on bilingual vocabulary alignment
2.5. Background of multilingual alignment of taxonomies
3. Statement of the problem
3.1. Research question
3.2. Objectives
4. Proposed methodology
4.1. Identification of the DMs of a language
4.2. Organization of the extracted DMs into groups
4.3. Labeling of clusters with functional categories
4.4. Populating the taxonomy with new specimens
4.5. Creation of a database of DMs in English, French, Spanish, German and Catalan
5. Dissemination of project results
5.1. Communication of results in the scientific field
5.2. Dissemination in society in general
6. International cooperation
7. Lines of future work
8. Publications derived from the project
References
1. Introduction
Discourse markers (DMs) constitute a large and heterogeneous set of linguistic units, not completely delimited but composed of functional elements - not lexical - which are used to guide the reader/listener, specifying the inferences he/she has to make in order to interpret the text according to the writer/speaker's intention and the contextual constraints. These elements do not participate in the semantics of the utterance, but serve to make propositions more cohesive or to regulate interaction. Some examples of these units are the following: for example, however, nevertheless, nevertheless, that is, therefore, on the one hand, first of all, certainly, among many others.
The use of DMs is very common in both writing and speaking and they have been studied in a great diversity of natural languages, such as Spanish, English, French, German, Chinese, Finnish, Italian, Japanese and Portuguese, and many others - even in sign languages. Their use has also been studied in a variety of genres and interaction contexts, such as narratives, political speeches, medical consultations, legal speeches, diaries, radio conversations and classrooms (Maschler & Schiffrin, 2015). DMs are present in different compositions in a great diversity of discursive genres, since they play a fundamental role in argumentation, exposition, narration and interaction in general.
Despite being an omnipresent phenomenon in language, it is only recently that linguists have approached it, and its exploration and delimitation has proved to be highly problematic (Fedriani & Sansò, 2017). There is a wide margin of disagreement among scholars regarding three aspects: 1) their delimitation as a set: definition of the necessary and sufficient conditions for a linguistic segment to be a DM; 2) their categorization: determining the functions they fulfill and which DMs correspond to each one; 3) their polyfunctionality: the fact that, depending on the context, a DM can have one function or another.
In this project we propose an analysis of DMs that is different from the introspective method that has prevailed in the study of this subject in its more than 30 years of existence in modern linguistics. In this case, the approach is based on quantitative linguistics: an inductive and corpus-driven analysis in which we do not start from previously established categories but rather these arise from the statistical analysis of large volumes of text. Our method is based on the analysis of large parallel corpora, the application of different statistical measures, and an especially designed clustering algorithm which allow us, on the one hand, to construct taxonomies of DMs that are emergent or natural in each of the languages and, on the other hand, to align these different taxonomies. Our approach is multilingual because we generate taxonomies in Spanish, English, French, German and Catalan, and because the method could hypothetically be applied to any other language.
The first intuition guiding our analysis is that the delimitation of DMs can be indicated by their distributional behavior. It is evident that certain discourse genres privilege certain DMs, but within each genre, and because they have no lexical content, DMs can appear in any text regardless of content. From there, for their categorization, we believe that it is possible to use the parallel corpus as if it were a sort of semantic mirror that allows us to see the functions of the DMs reflected: if two DMs in Spanish, such as sin embargo and no obstante, are systematically translated by the same DMs in English (however, nevertheless, etc.), this is then a strong indicator that both of them fulfill the same function.
This proposal is methodologically simple, computationally efficient and the results are accurate. We highlight the following aspects: 1) the categories are emergent, they do not come from the literature; 2) the method is powerful because it allows obtaining information about languages without requiring explicit knowledge of them; 3) this work can have practical applications in fields such as lexicography, discourse parsing, information extraction, machine translation, computer-assisted writing or language learning.
The methodology of discourse marker extraction and classification is based on parallel corpus data aligned at sentence level. From this parallel corpus we extract DM candidates and classify them using a clustering process. Clustering methods are a set of unsupervised classification algorithms that group elements based on the similarity between their components (Jain & Dubes, 1988; Manning & Schütze, 1999; Rokach & Maimon, 2005; Kaufman & Rousseeuw, 2009; Everitt et al., 2011; Gries, 2013; Divjak & Fieller, 2014; Brezina, 2018). The objective of clustering is therefore to identify partitions in an unstructured set of objects described according to their attributes/components (unsupervised classification). This identification is based only on these attributes and does not require any manually annotated data, a detail that for this research is fundamental, as it is what justifies that the categories are natural or emergent.
Regarding the data to be used as reference corpus for classification, this research resorts to the OPUS Corpus parallel data (Tiedemann, 2016), which provides sets of parallel corpora in various domains and genres, aligned at sentence level, in TMX format, a standard in the use of translation memories (Savourel, 2005). The corpus is publicly and freely available. So far, in this project we have used the Spanish-English, French-English, German-English and Spanish-Catalan language pairs. The number of words per language exceeds the billion tokens in most cases.
To process this data, we designed an algorithm to automatically read the TMX files and extract a first list of DM candidates aligned by language (Section 4.1). This interlinguistic alignment is then used for the intralinguistic alignment using the clustering technique (Section 4.2) from where the taxonomies are generated.
The multilingual taxonomy of DMs resulting of this process (Sections 4.3-4.5) consists of a data structure that brings together sets of DMs with an equivalent function and which are organized by language, which may be completely unknown to the person applying the method. In this way, we can access information such as how to counterargue in a given language, together with the list of examples that serve to do so (e.g. however, nevertheless), or to reformulate (in other words, that is to say), to introduce a digression (apropos, by the way), and so on.
Different researchers have proposed classifications of DMs using automatic methods (Knott, 1996; Knott & Mellish, 1996; Marcu, 1997a, 1997b; Alonso et al, 2002a, 2002b; Hutchinson, 2003, 2004, 2005; Muller et al., 2016; Webber et al., 2016, 2019), but they have started from predefined lists of markers and cover only certain types of elements. In our case, we include a wider variety of DMs and also prefer a language-agnostic model. The quantitative nature of our method offers a valuable complementary source of information to the classifications that other authors have previously derived with introspective methods.
In addition to its theoretical value, and because DMs are important signals of discourse structure (Popescu-Belis & Zufferey, 2006), this work has several practical applications. It could be used for discourse segmentation (or parsing), information extraction or machine translation, as well as in fields such as computer-assisted writing or language learning.
2. Related work
2.1. Research on Discourse Markers
As several authors have pointed out (Briz, 1993a, 1993b, Pons Bordería, 1996; 1998; Martín Zorraquino & Portolés, 1999; Cano Aguilar, 2003; Herrero, 2012), reference to some of these units was present in the more traditional grammars. For example, Bello (1847) noted that certain adverbial phrases such as ahora bien or ahora pues are transformed into continuative conjunctions to relate thoughts and the contents of certain segments of the text. Later, in the 20th century, in the closing chapter of his grammar, Gili-Gaya (1969) speaks of supra-sentential links to refer to formal mechanisms such as certain conjunctions, repetitions or anaphora which, although realized at the sentence level, make it possible to give coherence to the discourse as a unit. However, DMs have never been the focus of interest because their scope of action is usually supra-sentential, when both for traditional grammar and for 20th century linguistics until the appearance of text grammar, the unit of analysis was the sentence, at least as far as syntax or grammar is concerned. As a consequence of the above, interest in the study of DMs awakened relatively late in modern linguistics, when many linguists opened up to a functional explanation -pragmatic and discursive- of both sentence and supra-sentential elements (Llorente, 1996). However, at the moment when the subject finally began to come into focus, the difficulties were immediately evident (Portolés, 1993).
At the outset, it is possible to state that DMs are words of a grammatical and not lexical nature, since they are used to form grammatical constructions and not to refer to or predicate about entities of real or imaginary worlds nor to contribute any lexical meaning to propositions (Fraser, 1996). This leads us to consider DMs as inferential support units, since they facilitate the receiver's work of interpretation (Ler Soon Lay, 2006). However, they fulfill this function without participating in the sentence's structure, neither syntactically nor semantically, and it is not easy to characterize them syntactically. They come from very diverse grammatical categories, such as conjunctions (for example, but, although) and conjunctive locutions (so, so that), adverbs (besides, certainly) and adverbial expressions (therefore, of course), interjections (go, hey), performative expressions (I say, I think), prepositional phrases (by the way, in spite of that), among others. In addition to this heterogeneity of origins, DMs operate in different domains: they connect sentences, relate and organize textual segments and operate at the interpersonal level (Aijmer, 2022). In addition to the above, we find that many of them are polyfunctional, that is, they can fulfill different pragmatic functions in the discourse according to the clues provided in each case by the context (Fisher, 2006).
It is precisely the pragmatic and contextual conditions that pose the greatest difficulty for the grammarian in the task of syntactically characterizing DMs: although they usually maintain the syntactic properties of the grammatical classes from which they come (Martín Zorraquino & Portolés, 1999), they do not clearly present features that are necessary and sufficient, since DMs have an operational scope at the level of the utterance (communicative or pragmatic) and not at the sentence or grammatical level (Waltereit, 2006). In fact, many authors consider that DMs are a pragmatic category and therefore their rules are essentially different from those of sentence syntax (Martín Zorraquino & Portolés, 1999). This would be precisely what explains their role in the processing of coherence, cohesion, adequacy and effectiveness of discourse (Bazzanella, 2006).
From the point of view of the procedural approach, such as the one advocated by Sperber and Wilson (1986) and Blakemore (1987), DMs are conceived as guides to the interlocutor's inferences. From this point of view, a distinction is made between conceptual meaning, which can be analyzed in lexical terms, and procedural meaning, which refers to a specific pragmatic meaning that serves as a guide to follow the inferential path appropriate to the interpretation process. This distinction, however, does not prevent some elements, whose meaning is eminently procedural, from maintaining a veritative or conditional type of meaning. For example, a set of modal operators that some authors (e.g., Portolés, 1993) include as DMs (such as clearly, certainly, among others). These offer a conceptual representation that modifies the meaning of the whole utterance in which they appear, and therefore are not only functional. In this sense, DMs would work rather as metadiscursive signals that structure and organize the discourse. They are effective metalinguistic elements at the textual level (Lenk, 1997): they signal metalinguistic, metacommunicative, metapragmatic and metadiscursive mental processes (Maschler, 1994) that allow the speaker to step out of his propositional frame and metacommunicate his attitudes, positioning and feelings (Östman, 1981).
Functional criteria are the ones that seem to prevail in descriptions, at least in Spanish (e.g., Casado Velarde, 1993). It must be said, however, that the degree of disagreement between these authors is also important. Each of them considers different elements, concepts and properties to categorize DMs.
Naturally, the lack of consensus among specialists about the delimiting properties of the general category of DMs and the features that define the subcategories affects the certainty that one could have in these classifications (Loureda & Asín, 2010). It is a challenge, therefore, to find a way to overcome the subjectivity of the analyst, to clearly delimit the object of study and to establish taxonomies.
This is precisely the interest of the present research proposal. The particularity of this project is that it resorts to a fully inductive methodology, based on data obtained from large textual corpora for the extraction and classification of linguistic elements that can function as discourse markers. Another aspect of interest of our project is the multilingual integration, something that is uncommon in the related literature. Recently, there has been some interesting developments by another team of researchers who propose a multilingual database of connectives (Stede et al., 2019), a resource that allows for crosslinguistic comparison of discourse markers. There may be there some possibility for future collaboration, as with our automatic methods we could offer the possibility of populating that resource with new units extracted from different languages.
2.3. Background of automatic categorization of DMs
An automatic classification may involve the introduction of an objective measuring instrument as a means of overcoming the discussions involved in the subjectivity inherent in the introspective method commonly used in manual classifications of DMs. However, the main obstacle to an automatic classification is the lack of consensus among specialists on what are the class-delimiting properties of DMs. Alonso et al. (2002a) have attributed this lack of consensus to the preeminence of deductive approaches, with a significant bias for an underlying theory.The first proposals for formal mechanisms to detect and systematize DMs were made in the 1990s by Knott and Dale (1995). Later, Hutchinson (2004) applied machine learning algorithms to characterize discourse connectors and reported highly accurate results with respect to a gold standard. However, the learning of the models, as usual in this type of algorithms, depended on manually annotated instances, which on the one hand demands manual work prior to the applicability of the method and, on the other hand, necessarily implies a bias relative to the annotators. In their case, moreover, the method was restricted to units used to connect propositions and the classes to which connectors were assigned were manually decided, thus necessarily biased. Also, the evaluation of the results was based on previous manual classifications, so they were only able to recreate a similar classification or, perhaps, to validate the existing one.
Alonso et al. (2002b) proposed an approach to solve this problem, presenting the construction of a computational lexicon of DMs through the application of clustering techniques, with the aim of grouping instances of connector usage extracted from a large corpus. To do so, they relied on two sets of attributes: the first was derived from a manually coded lexicon of connectors containing syntactic and rhetorical information, the latter expressed in relations such as reinforcement, concession, consequence, etc.; the second, on the other hand, was derived from the surface processing of the text for the instances and defined attributes such as the position of the connector in the segment, the words surrounding it, the presence of negation, among others. The result was that the obtained clusters contain mainly instances in which the connectors have similar syntactic behavior. Although this proposal solves, in part, the previous problems, the fact that the selection of attributes was made from information extracted from a hand-coded lexicon of connectors implies that the agglomerated categories are only corroborated with corpus data instead of originating from the corpus. In addition to this restriction, the categories are limited, again, to the connecting function fulfilled by some DMs.
More recently, Muller et al. (2016) automatically obtained empirically grounded connector clusters based on the significance of the association between connectors and pairs of verbal predicates in context. To form the clusters, they used co-occurrence data collected from the Gigaword corpus of English (Graf & Scieri, 2003), and produced triplets of two predicates and a connector, along with the number of occurrences. They used the Penn Data Tree Bank (Prasad et al., 2008) list of DMs as a basis, without a priori clustering. Thus, they produced a matrix of {number of verb pairs} x {number of connectors} dimensions, so that each verb pair was represented by a set of attribute values. As in the previous case, extraction was limited to connecting elements and from a predefined list, again leading to an inevitable bias in the results.
2.4. Background on bilingual vocabulary alignment
The first antecedents of bilingual vocabulary extraction from corpora date back to the nineties of the last century and were based on the alignment of parallel corpora. Already in our century, however, the most successful approaches were proposals for bilingual vocabulary extraction from comparable (Gaussier et al., 2004) or even unrelated (Rapp, 1999) corpora.
With respect to the alignment of parallel corpora, perhaps the first antecedent dates back to 1822 with the decipherment of the Rosetta Stone carried out by Jean François Champollion (Véronis, 2000). A later antecedent can be the work of Weaver (1955), who already formulated the essence of the parallel corpus methodology, although his contribution was not understood by his contemporaries because the methods that prevailed in the field of machine translation of the time up until the 1990s were not of a quantitative or statistical nature but were instead based on rules.
The wave of parallel corpus alignment started in the 1990s in coincidence with a shift towards statistical methods, which proved to be robust as a basis for machine translation (Gale & Church, 1991; Brown et al., 1991; Och & Ney, 2003) Gale & Church (1991) started to generate bilingual vocabularies based on the calculation of cooccurrence in aligned sentences and this was followed by a long list of publications with different ideas to improve the results (Church, 1993). Some researchers proposed other ideas such as creating a virtuous circle between bilingual lexicon extraction and sentence alignment, feeding back results to improve the performance of each algorithm (Kay & Röscheisen, 1993) or incorporating explicit grammatical knowledge (Hiemstra, 1998).
It can be said, however, that this is a field that has matured and whose techniques have stabilized. A plateau seems to have been reached in terms of the performance quality of the algorithms, which has become quite high. With a near-perfect sentence alignment it is now possible to obtain a bilingual vocabulary with over 90% accuracy (Nazar, 2012).
2.5. Background of multilingual alignment of taxonomies
We find in the work of Jung (2008) and Jung et al. (2008) one of the first attempts to align taxonomies by looking for correspondences or similarities first between terms within the same taxonomy and later to align ontologies in different languages, presenting their first results in Korean and Swedish. More recently, publications along the same lines have started to appear. Declerck and Gromann (2012) proposed strategies for the alignment of lexical components in a multilingual ontology. Thomas et al. (2014) raise the issue of the alignment of multilingual taxonomies specialized in the financial field in French and Spanish using a logical reasoner. Finally, Mahdisoltani et al. (2015) present a multilingual alignment system for Wikipedia categories based on information that they extract mainly from the English version of WordNet, as a fundamental structure. They start from the category system and the Wikipedia's infoboxes, and they project this information to different languages.
Most of these taxonomies and ontologies contain nouns or noun phrases, i.e., elements of a syntactic and semantic behavior totally different from our object of study. However, we believe that these experiments represent a valuable methodological precedent. It is, in any case, an area of research that is still underdeveloped, despite the high practical impact that an automated solution would have. There are some precedents in the alignment of lexical ontologies in European languages such as EuroWordNet (projects LE-2 4003 and LE-4 8328) or our own previous work, Project Conicyt-Fondecyt 11140686, “Induccion automática de taxonomías de sustantivos generales y especializados a partir de corpus textuales desde el enfoque de la linguüística cuantitativa” (Automatic induction of taxonomies of general and specialized nouns from textual corpora from a quantitative linguistic approach. Lead researcher: Rogelio Nazar; years: 2014-2017).
3. Statement of the problem
3.1. Research question
- How to obtain a multilingual taxonomy of discourse markers from corpora.
3.2. Objectives
3.2.1. General Objective
- To obtain an automatic taxonomy of discourse markers in different languages from large multilingual parallel corpus data.
3.2.2. Specific Objectives
- To obtain a language-independent methodology for extracting discourse markers.
- To obtain a language-independent methodology for the categorization of discourse markers.
- To extract a multilingual taxonomy of discourse markers in multiple languages.
4. Proposed methodology
The main objective of this project was to obtain a methodology for the automatic extraction of a classification of discourse markers (DMs), both the categories and the members that constitute them, maintaining as a principle the disregard of linguistic resources already existing for a particular language, that is, through inductive processing of corpus data. The only input is a parallel corpus (PC), thus it is a method with the power of generalization, since it can be applied to any language without major adjustments. It is also an innovative method, since most of the research carried out with PC to date has been oriented towards the search for translation equivalences from one language to another. In contrast, the use of PC as an input for the extraction and organization of a taxonomy of DMs from the same language using an inductive approach is something that is being proposed for the first time with this project. In addition to obtaining the categories, the most valuable result is undoubtedly the exhaustive inventory of DMs that the method offers. From these results, it is possible to estimate that the total population of lexicalized DMs in a European language is close to one thousand units. In the case of the languages analyzed here, most of them are already in the project's database.
The general procedure is divided into four stages. The first consists of separating, from the vocabulary of a language, all those units that correspond to DMs. The second is to establish which are the categories of these DMs or, in other words, how they can be grouped. The third consists of recognizing the functions of these groups of DMs, if it is a category already known, in order to give names to the groups that are formed. The fourth, finally, is to use the taxonomy created to identify and classify new DM candidates.
4.1. Identification of the DMs of a language
The method chosen as the most effective, simple and generalizable is the filter by quantity of information. It was thus possible to successfully establish the first division of the vocabulary into lexical and functional categories thanks to the characteristic distribution of the latter in the corpus, a pattern determined by the fact that the appearance of a DM in a text is independent of the content of the texts. In operational terms, they show a uniform distribution and appear in the company of a large set of other words, which is indicative of a low quantity of information, since their occurrence does not generally help to predict the occurrence of other units. In contrast, a lexical content word such as democracy will show a more restricted word company, with units such as respect, rights, freedom, etc.
Figures 1 and 2 illustrate this difference, comparing the word democracy, in the first case, with the DM anyway. The co-occurrence profiles are different. In the first case, the area under the curve is larger in relative terms (i.e., ignoring the absolute frequency).
Figure 1: Frequency distribution of words cooccurring with words co-occurring with democracia (democracy).
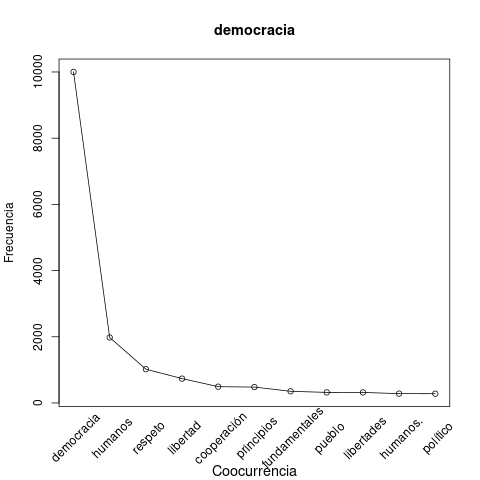
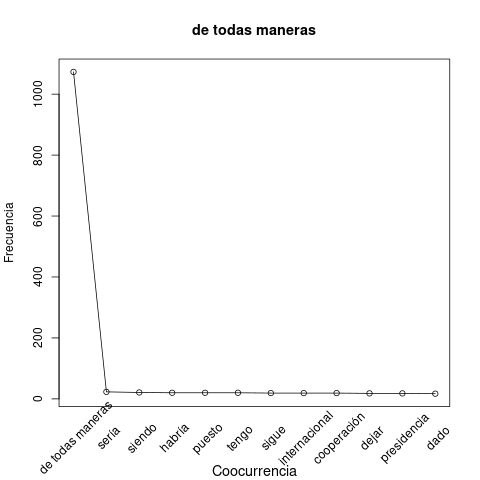
|
In order to capture this property, we define a coefficient (1), where  is a DM candidate;
is a DM candidate;  the set of co-occurring words;
the set of co-occurring words;  the set of contexts of and
the set of contexts of and  is the frequency of the word at position
is the frequency of the word at position  from the list of the
from the list of the  most frequent in those contexts (in our experiments,
most frequent in those contexts (in our experiments,  ).
).
 |
(1) |
At one extreme, this coefficient produces a very low value for function words such as articles, conjunctions, prepositions, etc. At the opposite extreme are, on the other hand, the more specialized vocabulary words. The cutoff value of this continuum between lexical ( ) and functional (
) and functional ( ) category is given by an arbitrary parameter
) category is given by an arbitrary parameter  (2).
(2).
 |
(2) |
4.2. Organization of the extracted DMs into groups
For this task, we developed a new clustering algorithm that is characterized by its computational efficiency, which is necessary to be able to process such a large data set. As a similarity measure to group the extracted DMs in the previous step, this algorithm uses the common equivalence of the DMs in a second language, hence the recourse to the PC. This is effectively using the PC as a semantic mirror. For example, the DMs however and nevertheless are similar because both have sin embargo and no obstante, among others, as equivalents in Spanish. Obtaining these first cross-linguistic equivalences in the parallel corpus is then used to find the corresponding intralinguistic similarities. To find these equivalences we apply an association coefficient (3) based on the co-occurrence of the elements in the aligned segments. With this coefficient we establish the probability that the DM in language is equivalent to the DM  in language
in language  .
.
 |
(3) |
Once the list of interlinguistically aligned DM pairs is obtained, the clustering process begins to obtain the intralinguistic similarities. For each pair in this set, such as the pair por esa razón  for that reason, it is checked whether either of the two has been present in a previously examined pair. If a pair por esta razón for that reason,
is later found, it may be assumed that por esta razón y
por esa razón are similar, without the need to look at their lexical or orthographic similarity. When such a similarity is found, the new DM is added to the already formed cluster. Figure 3 illustrates a moment in the process, when a new DM for that reason is added to a previously formed cluster.
for that reason, it is checked whether either of the two has been present in a previously examined pair. If a pair por esta razón for that reason,
is later found, it may be assumed that por esta razón y
por esa razón are similar, without the need to look at their lexical or orthographic similarity. When such a similarity is found, the new DM is added to the already formed cluster. Figure 3 illustrates a moment in the process, when a new DM for that reason is added to a previously formed cluster.
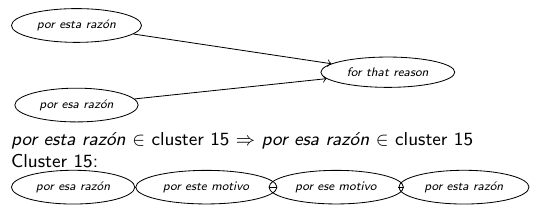
|
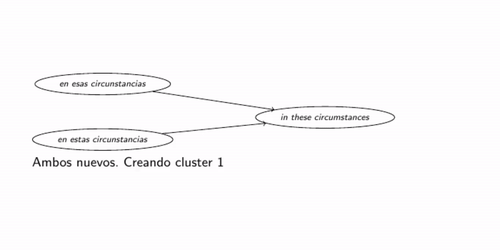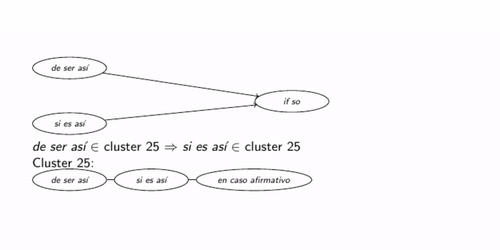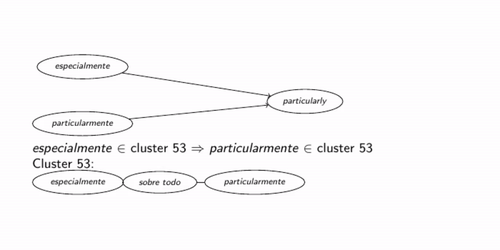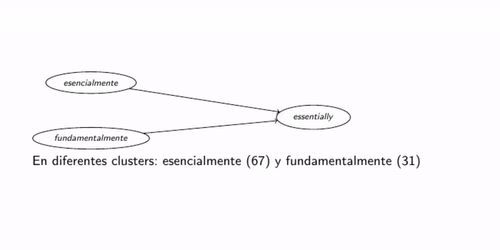
|
4.3. Labeling of clusters with functional categories
The previous step results in an indeterminate number of DM clusters in each language, although at this point the system only identifies them with arbitrary numerical codes. In order to give these clusters meaningful names, a list of arbitrary names for the most general categories was compiled along with two to three DM examples for each. This allows automatic labeling of the clusters by grouping them into these categories, which is achieved by calculating the intersection (4) between these examples ( ) and the members of each cluster (
) and the members of each cluster ( ).
).
 |
(4) |
4.4. Populating the taxonomy with new specimens
Once a basic DM taxonomy has been formed, it is used to classify new DMs recursively. Given a candidate DM, it is first classified by language, then it is decided whether it is a DM and, if so, assigned a category. For both tasks we use the same PC. If the candidate is a genuine DM, its status will be indicted by the PC. For example, a candidate as de la misma manera will have as equivalents according to the PC elements such as in the same way, likewise, similarly, etc., which are already registered in the taxonomy as English DMs. It is then concluded that the candidate is genuine and belongs to the same category.
4.5. Creation of a database of DMs in English, French, Spanish, German and Catalan
At present, the results of the project imply the creation of a multilingual DM taxonomy, with 2,897 elements, 619 in Spanish, 733 in English, 556 in French, 677 in German, and 312 in Catalan, divided into 70 functional categories. Table 1 shows an example of one of the clusters, labeled with the category of contrastive connectors. The full multilingual taxonomy resulting from the project is also available for download.
|
A manual evaluation campaign of these results was carried out by native speakers of each language, collaborators or technical staff of the project with periodic meetings to maintain uniformity of criteria. The evaluation process consisted of the following two phases. The first was to determine the accuracy of the algorithm, defined as the proportion of correct DMs in the extracted taxonomy. For this we checked the completeness of the database to record cases where it is not a genuine DM, is poorly segmented, or misclassified. In all languages we found an error rate of less than 5% except in German, where the error reached 16%, mainly due to segmentation problems. The second phase consisted of the evaluation of coverage, defined as the proportion of DMs of a language that are contained in the taxonomy. For this we took random samples of 10 texts per language and quantified the proportion of DMs appearing in those texts that were not in our taxonomy. In this way we were able to estimate the total coverage of this resource at 88%.
5. Dissemination of project results
5.1. Communication of results in the scientific field
The results of the project have already been published in scientific journals [Nazar 2021a, Nazar 2021b] and have been presented at 10 international linguistic conferences. In addition, 12 undergraduate theses and one doctoral thesis were defended based on data and methods developed in the project. Some publications have also derived from some of these theses, such as [Asenjo y Nazar 2020], [Robledo y Nazar 2023] and [Alvarado y Nazar 2024].
5.2. Outreach to the general public
In addition to the communication of result research in scientific forums, this project has also invested in outreach to the general public. Some of that consisted of the development of this website (http://www.tecling.com/dismark), which contains the complete DM database in the languages we have worked with, detailed documentation and an implementation of the DM classifier prototype, which allows the user to reproduce experiments by entering one or more DM candidates.
In addition to this website, we have invested in the creation of short videos explaining different phases of the project and possible applications.
Video presentation of the DM Dictionary (in Spanish):
Description of the methodology (in Spanish):
Video presentation of the project (in English):
6. International cooperation
The project sparked some international cooperation thanks to the collaboration of Professors David Lindemann (University of the Basque Country) and Antonio Balvet (University of Lille), who reviewed results and provided feedback on the German and French data, respectively. It is also worth mentioning here the short research stay of the main researcher at Universidad Nacional de Cuyo (Argentina), with the objective of collaborating with the research group that carries out the Corpus Espada Project. Given the interest that this group has in the study of textual genres, there is a common area of interest between both projects, which is the study of the correlation between the use of DMs and textual genres.
7. Lines of future work
This project set out to design and evaluate a methodology, and for this reason it was applied only to a small group of languages. Now that the method is established, a first phase of future work will consist of replicating experiments in different languages. Moreover, the project was limited to the synchronic study of DMs, but the algorithm is designed to operate dynamically, so the diachronic study presents itself as an attractive possibility for future work, to document the process of DM grammaticalization.
8. Publications derived from the project
People involved in the project
Lead researcher :
Rogelio Nazar
Co-researcher:
Irene Renau
Collaborator:
Hernán Robledo
International collaborators:
David Lindemann
Antonio Balvet
Research assistants:
Nicolás Acosta
Andrea Alcaíno
Patricio Arriagada
Scarlette Gatica
Ricardo Martínez
Natalie Mies
Mathilde Guernut
Maureen Noble
Valentina Ravest
Diego Sánchez
Jana Strohbach
Theses funded by this project:
PhD Thesis:
Hernán Robledo Nakagawa (2021). Categorización de los marcadores del discurso del español: una propuesta inductiva guiada por corpus paralelo. PDF
Undergraduate theses:
Héctor Ramos (2022).Polifuncionalidad de los marcadores discursivos conectores en textos científicos y literarios.
Gabriela Paz Cacciuttolo Provoste (2022). Estudio cuantitativo de variables estilísticas en la traducción literaria.
Pedro Andrés Bolbarán Gálvez (2022). Análisis descriptivo de la incidencia de errores en transcriptores automáticos.
Camila Pérez Lagos (2022). Extracción y clasificación de neologismos especializados en un corpus de divulgación científica de astronomía.
Javiera Silva Espinoza (2022). Estudio comparativo del aprendizaje de neologismos en hispanohablantes en una traducción y una interpretación.
Bahony Saavedra Tapia (2022). Análisis comparativo para establecer la relación entre la condición de un préstamo y su categoría gramatical.
Belén Guerrero Carreño (2021). Análisis contrastivo del uso de préstamos simples en las variantes chilena y peninsular del castellano.
Camila Alvarado Barbosa (2020). Detección de marcadores discursivos: el caso de los conectores causal-consecutivos y su polifuncionalidad.
Sara Asenjo Sotelo (2019). Estudio descriptivo del uso de marcadores discursivos en niños de 7 años con trastorno específico del lenguaje.
José Bahamonde Cano (2019). La terminología médica en la traducción audiovisual: análisis de la terminología médica en subtítulos profesionales y fansub de textos audiovisuales no especializados.
Paolo Caballería Rodríguez (2019). Modelo algorítmico para el reconocimiento automático de referentes y la resolución de anáfora pronominal en textos en español.
Yerko Leiva (2019). Análisis de modalizadores en el discurso de revistas psiquiátricas chilenas y españolas.