HAT - Herencia, Asimetría, Transitividad
(Inheritance, asymmetry, transitivity)
This is the accompanying website of the following paper (written in Spanish):
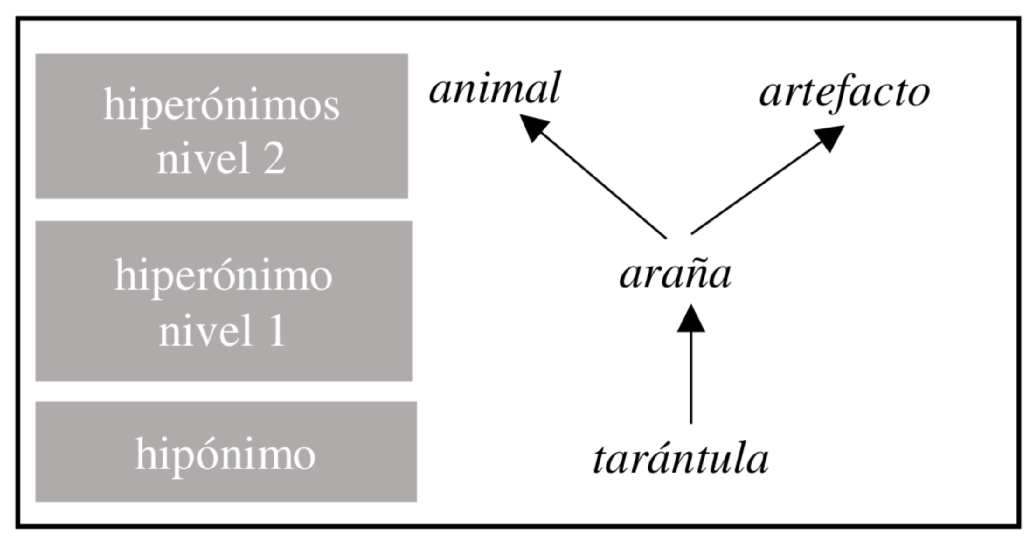
Rogelio Nazar; Javier Obreque; Irene Renau (2020). Tarántula –> araña –> animal : asignación de hiperónimos de segundo nivel basada en métodos de similitud distribucional. Procesamiento del Lenguaje Natural, Revista nº 64, marzo de 2020, pp. 29-36.
http://journal.sepln.org/sepln/ojs/ojs/index.php/pln/article/download/6192/3643
Tarantula –> spider –> animal: second level hypernymy discovery based on distributional similarity methods
Abstract:
Automatic hypernymy discovery continues to present challenges for natural language processing. Polysemous nouns are linked to more than one hypernym and can therefore cause structural damage on a lexical taxonomy. For instance, the Spanish noun tarántula (`tarantula') is a hyponym of araña (`spider'), but this is also a polysemous noun, as it means `chandelier' as well. It is thus necessary to determine the next hypernym in the chain, that is animal (`animal') or artefacto (`artifact'). In this paper we explore methods to solve this problem using a similarity measure that uses verb-noun co-occurrence as a predictor variable. Best results (84% success) are obtained with a simple method that only measures co-occurrence, irrespective of any syntactic information.
Documentation and source code of the project:
0. The corpus
The corpus consists of a random sample of up to 5,000 contexts of occurrence of the analyzed nouns, taken from the EsTenTen corpus and tagged with TreeTagger.
Download the sample of contexts (145,2Mb).
1. The script to obtain a sample of triplets from WordNet
This sampling script is here for documentation purposes and has no practical use. Most users will prefer to skip this part and go directly to section 2.
This script is the first we mention in the paper, and is devoted to the extraction of candidates from a copy of WordNet taken from Freeling. These candidates are nouns which happen to have more than one hypernym and are therefore raw material for the production of the data needed for our experiments, i.e., triplets of the type mentioned in the title. For convenience, we include also the formatted copy of WordNet. Just check that the path to this file is correct. Anyway the script will complain if not.
Usage:
perl buscapoli.pl > rawmaterial.txt
We used the raw material produced by the script as input to generate a list of triplets with enough frequency in the corpus (100 occurrences as a minimum). But we used other sources as well, such as the Kind Taxonomy, plus examples that came to mind. Part of our pending work now is to extend experimentation with larger datasets, and then update this website accordingly. The sample we used in the paper is also included in the downloadable zip file. Remember to unzip before running.
Download buscapoli.pl
Download the copy of WordNet (483kB)
2. The one script that worked: ponderado.pl
In the paper we report on different experiments with variants of the algorithm. The original source code of the project thus consists of a series of Perl scripts, each of them representing one of the variants. As explained in the paper, however, many of those attempts were unsuccessful. We believe, therefore, that it only has sense to publish here the code of the script that performed best, which is the one we call ponderado.pl. At some point in the future we hope to be able to clean and publish the code of our unsuccessful attempts as well (i.e., binario.pl, euclideano.pl and dependencias.pl), as some reader could find out why those attempts failed and maybe do something about it.
Download ponderado.pl
Usage:
perl ponderado.pl
Remember to unzip before running!
If you have doubts or something goes wrong, drop a line: rogelio dot nazar at pucv dot cl